

一、定时器使用场景定时器的使用普遍存在于各个场景中,比如:1. 心跳机制,客户端定期向服务端发送心跳信息2. TCP可靠性传输,一段时间内没有收到响应时重新发送数据包3. 每天10点为客户生成对账单4. 每年双11的0点开启秒杀
5. 各类MQ的延时消息6. js中的setInterval一般定时任务的形式表现有三:1. 经过固定时间后触发2. 按照固定频率周期性触发3. 在某个时刻触发二、基础前提当提交一个定时任务的时候,这个任务被执行的时间点是明确的,不管这个时间点是相对于当前的时间(如:30s后执行)还是确切指定的时间点(如:2021-09-10 12:22:05执行)
三、简易的定时器

一个数组 + 一个线程 就可实现定时器的功能,线程每隔一段固定时间(如每500ms)去检查一下列表,如果有任务到期,就取出来执行但这种方式存在3个明显的缺点:1. 如果数组长度很长的话,每次轮询的时候也会比较长。
2. 如果线程轮询的频率高了(如:1ms一次),就会导致CPU占用过高,如果轮询频率低了,又会导致任务处理不及时3. 如果一个任务执行的时间比较长,那在它后面的任务会被延迟执行四、定时器优化方案对于第1个问题
,由于每个任务的执行时间是确定的,所以,在添加任务的时候,我们完全可以按将要执行时间的先后排序,先执行的排在前面,后执行的排在后面,这样,每次轮询的时候只需要判断第一个是否已到达执行时间即可

对于第2个问题,可以采用“非固定”时间轮询,即执行完一次任务的时候,算一下第一个任务执行的时间间隔是多久(如:30s),然后让线程休眠30s后再执行不过这样做又带来另一个问题,假设线程休眠期间又新增了一个任务,这个任务要在10s后执行,但是前面已设定了线程休眠30s,这不就会导致现在添加的任务会被延迟执行了吗?这个好解决,添加任务的时候判断一下这个添加进去的任务是不是排在第一位,如果是的话唤醒线程,重新设置休眠时间。
Java提供的java.util.Timer和DelayQueue都采用了这种策略对于第3个问题,也好解决,我们把轮询的线程和执行任务的线程分开不就行了,可以用一个线程来进行轮询,用多个线程来执行任务,所以java.util.concurrent.ScheduledThreadPoolExecutor这个定时任务线程池就出来了。
Timer和ScheduledThreadPoolExecutor都是定时规则和执行的任务一同提交,到点就自动执行任务,而java.util.concurrent.DelayQueue也提供了延时功能,不同的是DelayQueue需要客户端线程自行去轮询和执行任务,在轮询的时候,如果任务还未到期就不会返回数据,如果任务已到期,就会返回任务,然后客户端拿到任务之后自行决定怎么处理(如:立马放到线程池中执行)。
注:实际上的DelayQueue、ScheduledThreadPoolExecutor原理并没有那么简单,还做了其他很多的优化和处理,不过定时设计的思路上大体差不远五、时间轮在一般情况下,上面的方案也够用了,但如果是几十万、上百万、上千万的定时任务(如:MQ延时消息),那么每个任务在插入到队列中在进行排序时,这个耗费的时间就相当可观了,所以,还需要进一步的优化。
我们来看看时间轮方案,如下图:
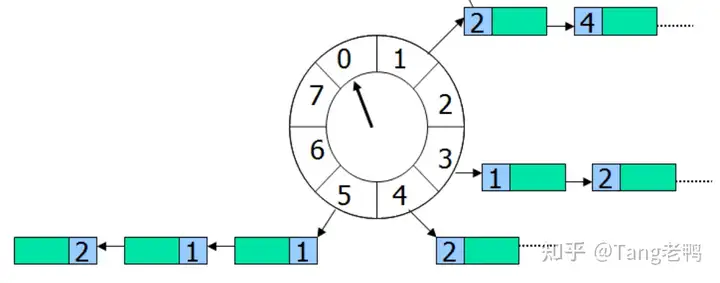
上图是一个长度为8的循环队列,假设该时间轮精度为秒,即每秒走一格,走完一圈就是8秒每个格子指向一个任务集合(可理解为跟前面的DelayQueue结构一样),时间轮无限循环,每转到一个格子,就扫描该格子下面的所有任务,把时间到期的任务取出来执行。
举个例子,假设指针当前正指向格子2,来了一个任务需要4秒后执行,那么这个任务就会放在格子6下面,如果来了一个任务需要20秒后执行怎么?由于这个循环队列转一圈只需要8秒,这个任务需要多转2圈,所以这个任务的位置虽然依旧在格子6(20%8+2=6)下面,不过需要多转2圈后才执行。
因此每个任务需要有一个字段记录剩余圈数,每转一圈就减1,减到0则立刻取出来执行 当任务添加进来的时候,指针可能落在任意一个格子上,所以需要有个公式来计算新添加在任务应该放在哪个格子上,公式为:任务位置
= 延时时间 % 轮的长度 + 当前位置,如果这公式算出的“任务位置”大于时间轮长度,则再取一次模(注意:在进行公式计算之前,延时时间 的单位需要转换成当前时间轮所使用的时间单位,并且向上取整) 通过这种方式,我们可以把任务相对分散的散落在各个格子中(也叫任务槽),那在插入、删除任务的时候,比起单条链的列表来说可以省下不少时间(因为从单链条变成了多链条)。
不过这也带来另一个问题,因为每转到一个槽的时候,需要把槽里面的每一个任务都取出来,把剩余圈数减去1,如果某些个任务的剩余圈数很大,就会造成太多次检测,让CPU白白空转了那么多次为了解决这个问题,一种方式是增加槽的数量,但这会增加内存消耗,一种方式是增加每个槽的时间范围,但这又会降低定时精度,这两种方式都不是那么好,所以还需进一步的优化成层级时间轮。
注:时间轮在netty中有实现:链接地址,netty中的任务执行使用异步方案,避免任务执行阻塞轮询任务的线程六、层级时间轮
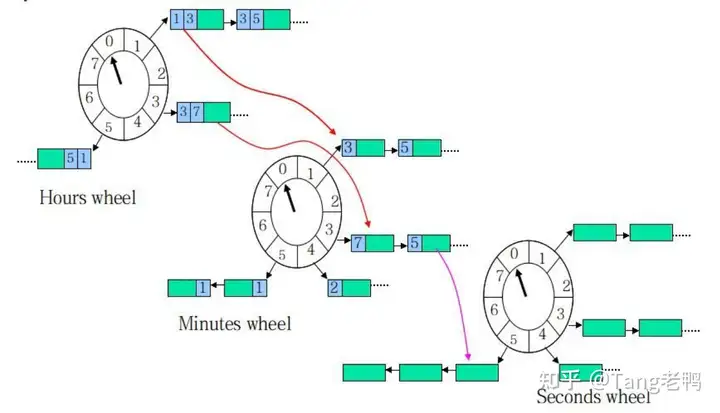
层级时间轮,分多个时间轮,以上图为例,第1层,每格的时间跨度为1s,那么第1层总的时间跨度为8s,第2层的每格时间跨度就为8s,第2层总的时间跨度就为8 * 8 = 64s,第3层的每格时间跨度就为64s,第3层总的时间跨度就为8 * 64 = 512s,第1层转完一圈,触发第2层转动一格,第2层转一圈触发第3层转一格,这个思想跟时钟是一模一样的,时钟有秒针、分针、时针,秒针的刻度为60格,每格1s,分针的刻度也是60格,每格60s,时针的刻度为12,每格3600s,如下图:

在添加任务的时候,先看第1层的时间跨度够不够,够的话就落在第1层,不够的话再判断第2层,第2层还不够的话再判断第3层,这是一个层级递升的过程 在检测是否需要任务触发的过程跟上面刚好反过来,是一个降级的过程,假设现在所有指针都在0刻度,现在添加一个800s延迟的任务,那它肯定落在第3层,转1圈后还剩余288秒(800 - 512 * 1 = 288),这个时候圈数为0了,但是又还没到触发的时间,那就往第2层放,在第2层转4圈后还剩余32秒(288 - 64 * 4 = 32),这时,也还没到触发时间,继续往第1层放,在第1层转4圈后(32 - 8 * 4 = 0),剩余圈数为0了,剩余时间也为0了,此时到达触发时间,取出来执行即可。
注:层级时间轮在kafka中有实现,博客参考地址,时间轮就是计算机世界对现实世界中时钟的映射七、Quartz定时任务调度框架其实,Quartz定时任务的设计基本也是遵循上面的思路的,然后在此基础之上增加了集群管理,数据持久化、cron表达式支持等等的处理,变成了一个功能强大的定时任务框架。
这边有个疑问的是,在Quartz中不但支持直接指定任务触发频率或延迟时间,它还支持Cron表达式的定时任务的,但是在我们上面说到的那些方案中,并没有说到,那Quartz是怎么实现的?其实Cron表达式的定时任务就是多了一个转换,因为Cron表达式本身是有规则的,我们可以根据Cron表达式,计算出这个任务下次执行的确切时间,这不就又可以使用时间轮了嘛。
关于Cron表达式的解析,可以查看org.quartz.Cronexpression这个类的源码Cron表达式的规则和样例如下:


除了支持Cron表达式,Quartz中的任务还有可持久化的特点,可把任务储存到Mysql等数据库中,重启的时候,任务不会丢失,这个原理其实也好理解,在时间轮的基础上,定期的把数据库中在近期一段时间内(如30秒内)将要执行的任务放到时间轮内不就可以了嘛。
除了提供丰富的时间表达式和触发规则之外,Quartz还加入了集群功能,能够有效的实现故障转移和负载均衡,并且提供了相应的API对任务进行添加、修改、暂停、触发、删除等操作,使定时任务的管理变得非常的灵活和方便。
参考文档定时器:https://cloud.tencent.com/developer/article/1404012定时器:https://soulmachine.gitbooks.io/system-design/content/cn/task-scheduler.html
Kafka时间轮:https://juejin.im/entry/6844903616671662088Quartz:https://www.jianshu.com/p/7e755698d58aQuartz:
https://juejin.im/post/5c3bf24951882523d3201c54Cron表达式解析:https://www.jianshu.com/p/fb92bdf7a093Cron表达式:
https://www.cnblogs.com/zy-jiayou/p/7007303.html
 sdf
sdf