

什么是定时器?定时器提供在指定的时间触发执行的功能定时器的应用非常普遍,比如定时触发秒杀活动、定时清理日志、定时发送心跳信息等实现定时器的方法多种多样,古代有采用水漏或者沙漏的方式,近代有采用机械的方式(各种各样的时钟),数字脉冲,元素衰减等方式。
在计算机领域有2种形式,一种是硬件定时器,一种是软件定时器硬件定时器的原理是计算时钟脉冲,当规定的时钟脉冲之后由硬件触发中断程序执行,硬件定时器一般是芯片自带的,硬件定时器时间比较精准但是数量有限,因此人们又发明了软件定时器。
软件定时器由软件统计计算机时钟个数,然后触发对应的任务执行,由于是纯软件实现,理论上可以创建很多个,下面我们主要看下软件定时器的实现 定时器的实现1.双向链表首先我们想到的是把定时任务放入一个队列中,每隔固定的时间(一个tick)去检查队列中是否有超时的任务,如果有,则触发执行该任务。
这样做的好处是实现简单,但是每次都需要轮询整个队列来找到谁需要被触发,当队列的长度很大时,每个固定时间都需要去轮询一次队列,时间开销比较大当我们需要删除一个任务的时候,也需要轮询一遍队列找到需要删除的任务,实际上我们可以优化一下用双向链表去实现队列,这样删除的任务的时间复杂度就是O(1)了。
总结一下就是采用双向链表实现队列,插入的时间复杂度是O(1),删除的时间复杂度也是O(1),但是查询的时间复杂度是O(n)

双向链表任务队列2.最小堆最小堆的实现方式是为了解决上述查找的时候需要遍历整个链表的问题,我们知道最小堆中堆顶的元素就是最小的元素,每次我们只需要检查堆顶的元素是否超时,超时则弹出执行,然后再检查新的堆顶元素是否超时,这样查找可执行任务的时间复杂度约等于O(1),最小堆虽然提高了查找的时间,但是插入和删除任务的时间复杂度为O(log2n)。
下面我们看一个例子 堆中节点的值存放的是任务到期的时间,每隔1分钟判断下是否有任务需要执行,比如任务A是19:01分触发,周期为5分钟,任务B是19:02分触发,周期为10分钟,那么第一次最小堆弹出19:01,执行之后,在堆中重新插入19:06分的任务A,这时候任务B到了堆顶,1分钟之后检测需要执行任务B,执行完成后,在堆中重新插入19:12分的任务B。
然后循环执行上述过程每执行一次任务都需要重新插入任务到堆中,当任务频繁执行的时候,插入任务的开销也不容忽略
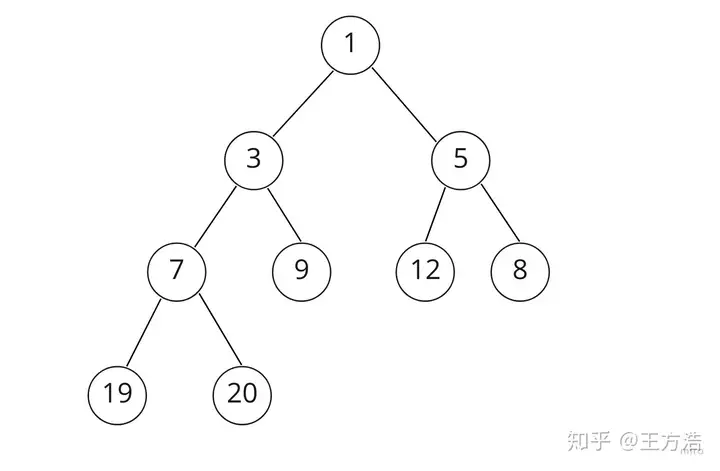
最小任务堆3.时间轮最后,我们介绍一种插入、删除和触发执行都是O(1)的方法,由计算机科学家"George Varghese"等提出,在NetBSD(一种操作系统)上实现并替代了早期内核中的callout定时器实现。
最原始的时间轮如下图

时间轮一共有8个bucket,每个bucket代表tick的时间,类似于时钟,每个1秒钟走一格,我们可以定义tick的时间为1秒钟,那么bucket[1]就代表第1秒,而bucket[8]就代表第8秒,然后循环进行上述步骤。
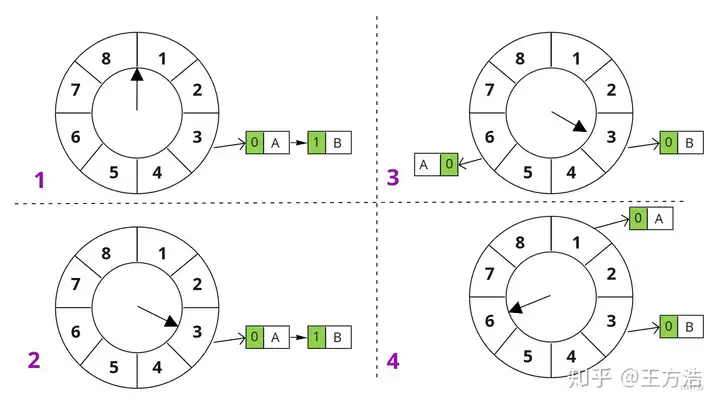
一个bucket中可能有多个任务,每个任务采用链表的方式连接起来下面通过一个例子来说明如何添加、删除和查找任务 假设时间轮中有8个bucket,每个bucket占用一个tick时间,每个tick为1秒。
当前有2个定时任务A、B,分别需要3秒、11秒执行一次目前指针指在0的位置,3秒钟之后指针将指向bucket[3]的位置,因此我们把任务A放入bucket[3]中,接下来我们再看如何放置任务B,任务B是11秒之后执行,也就是说时间轮转1圈之后,再过3秒种,任务B才执行,那么如何标记任务的圈数呢?这里引入了round的概念,round为1就表示需要1圈,如果round为2则需要2圈,同理推广到其它圈数。
我们把B任务也放入bucket[3],但是设置它的round为1我们先看下任务A和任务B的执行过程,3秒钟之后时间轮转到bucket[3],这时候检查bucket[3]中的任务,只执行round为0的任务,这里执行任务A,然后把bucket[3]中所有任务的round减1,这时候任务B的round数为0了,等到时间轮转一圈之后,就会执行任务B了。
这里还有一个疑问就是任务A执行完成之后,下一次触发如何执行,其实在bucket[3]执行完成之后,会把任务A从bucket[3]中删除,然后从新计算3+3,放入bucket[6]中,等到bucket[6]执行完成之后,然后再放入(6+3)对8取余,放入bucket[1]中。
也就是说每次任务执行完成之后需要重新计算任务在哪个bucket,然后放入对应的bucket中
可以看到时间轮算法的插入复杂度是O(1),删除的复杂度也是O(1),查找执行的复杂度也是O(1),因此时间轮实现的定时器非常高效 Cyber定时器实现用户接口Timer对象是开放给用户的接口,主要实现了定时器的配置"TimerOption",启动定时器和关闭定时器3个接口。
我们首先看下定时器的配置TimerOption(uint32_tperiod,std::functioncallback,booloneshot):period(period),callback
(callback),oneshot(oneshot){}包括:定时器周期、回调函数、一次触发还是周期触发(默认为周期触发) Timer对象主要的实现都在"Start()"中 voidTimer::
Start(){// 1. 首先判断定时器是否已经启动 if(!started_.exchange(true)){// 2. 初始化任务 if(InitTimerTask()){// 3. 在时间轮中增加任务
timing_wheel_->AddTask(task_);AINFO<<"start timer ["
如果定时器没有启动,则初始化定时任务在时间轮中增加任务那么初始化任务中做了哪些事情呢? boolTimer::InitTimerTask(){// 1. 初始化定时任务 task_.reset(new。
TimerTask(timer_id_));task_->interval_ms=timer_opt_.period;task_->next_fire_duration_ms=task_->interval_ms
;// 2. 是否单次触发 if(timer_opt_.oneshot){std::weak_ptrtask_weak_ptr=task_;// 3. 注册任务回调 task_->
callback=[callback=this->timer_opt_.callback,task_weak_ptr](){autotask=task_weak_ptr.lock();if(task){
std::lock_guardlg(task->mutex);callback();}};}else{std::weak_ptrtask_weak_ptr=
task_;// 注册任务回调 task_->callback=[callback=this->timer_opt_.callback,task_weak_ptr](){std::lock_guard<
std::mutex>lg(task->mutex);autostart=Time::MonoTime().Tonanosecond();callback();autoend=Time::MonoTime
().Tonanosecond();uint64_texecute_time_ns=end-start;if(task->last_execute_time_ns==0){task->last_execute_time_ns
=start;}else{// start - task->last_execute_time_ns 为2次执行真实间隔时间,task->interval_ms是设定的间隔时间 // 注意误差会修复补偿,因此这里用的是累计,2次误差会抵消,保持绝对误差为0
task->accumulated_error_ns+=start-task->last_execute_time_ns-task->interval_ms*1000000;}task->last_execute_time_ns
=start;// 如果执行时间大于任务周期时间,则下一个tick马上执行 if(execute_time_ms>=task->interval_ms){task->next_fire_duration_ms
=TIMER_RESOLUTION_MS;}else{int64_taccumulated_error_ms=::llround(static_cast(task->accumulated_error_ns
)/1e6);if(static_cast(task->interval_ms-execute_time_ms-TIMER_RESOLUTION_MS)>=accumulated_error_ms
){// 这里会补偿误差 task->next_fire_duration_ms=task->interval_ms-execute_time_ms-accumulated_error_ms;}else
{task->next_fire_duration_ms=TIMER_RESOLUTION_MS;}}TimingWheel::Instance()->AddTask(task);};}returntrue
;}下面对Timer中初始化任务的过程做一些解释 在Timer对象中创建Task任务并注册回调"task_->callback",任务回调中首先会调用用户传入的"callback()"函数,然后把新的任务放入下一个时间轮bucket中,对应到代码就是"TimingWheel::Instance()->AddTask(task)"。
task->next_fire_duration_ms是任务下一次执行的间隔,这个间隔是以task执行完成之后为起始时间的,因为每次插入新任务到时间轮都是在用户"callback"函数执行之后进行的,因此这里的时间起点也是以这个时间为准。
task->accumulated_error_ns是累计时间误差,注意这个误差是累计的,而且每次插入任务的时候都会修复这个误差,因此这个误差不会一直增大,也就是说假设你第一次执行的比较早,那么累计误差为负值,下次执行的时间间隔就会变长,如果第一次执行的时间比较晚,那么累计误差为正值,下次执行的时间间隔就会缩短。
通过动态的调节,保持绝对的时间执行间隔一致

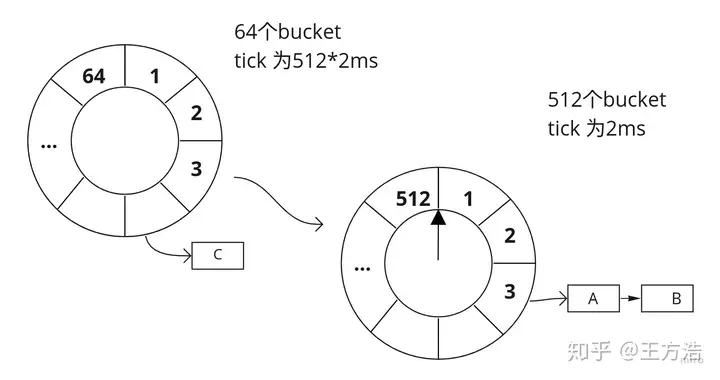
TimingWheel时间轮接下来看时间轮TimingWheel的实现,TimingWheel时间轮的配置如下:512个bucket64个roundtick为2msTimingWheel是通过AddTask调用执行的,下面是具体过程。
voidTimingWheel::AddTask(conststd::shared_ptr&task,constuint64_tcurrent_work_wheel_index){
// 1.不是运行状态则启动时间轮 if(!running_){// 2.启动Tick线程,并且加入scheduler调度 Start();}// 3. 计算一下轮bucket编号 autowork_wheel_index。
=current_work_wheel_index+task->next_fire_duration_ms/TIMER_RESOLUTION_MS;// 4. 如果超过最大的bucket数 if(work_wheel_index
>=WORK_WHEEL_SIZE){autoreal_work_wheel_index=GetWorkWheelIndex(work_wheel_index);task->remainder_interval_ms
=real_work_wheel_index;autoassistant_ticks=work_wheel_index/WORK_WHEEL_SIZE;// 5.疑问,如果转了一圈之后,为什么直接加入剩余的bucket???
if(assistant_ticks==1&&real_work_wheel_index!=current_work_wheel_index_){work_wheel_[real_work_wheel_index
].AddTask(task);ADEBUG<<"add task to work wheel. index :"<
=0;{// 6.如果超出,则放入上一级时间轮中 std::lock_guardlock(current_assistant_wheel_index_mutex_);assistant_wheel_index
=GetAssistantWheelIndex(current_assistant_wheel_index_+assistant_ticks);assistant_wheel_[assistant_wheel_index
].AddTask(task);}ADEBUG<<"add task to assistant wheel. index : "<
work_wheel_[work_wheel_index].AddTask(task);ADEBUG<<"add task ["
也就是说主线程单独执行时间计数,而具体的定时任务开多个协程去执行,可以并发执行多个定时任务定时任务中最好不要引入阻塞的操作,或者执行时间过长 2. Cyber定时器中引入了2级时间轮的方法(消息队列kafka中也是类似实现),类似时钟的小时指针和分钟指针,当一级时间轮触发完成之后,再移动到二级时间轮中执行。
第二级时间轮不能超过一圈,因此定时器的最大定时时间为64*512*2ms,最大不超过约65s
Tick接下来我们看下时间轮中的Tick是如何工作的在上述"AddTask"中会调用"Start"函数启动一个线程,线程执行"TickFunc" voidTimingWheel::TickFunc()
{Raterate(TIMER_RESOLUTION_MS*1000000);// ms to ns // 1. 循环调用 while(running_){// 2. 执行bucket中的回调,并且删除当前bucket中的任务(回调中会增加新的任务到bucket)
Tick();tick_count_++;// 3. 休眠一个Tick rate.Sleep();{std::lock_guardlock(current_work_wheel_index_mutex_
);// 4.获取当前bucket id,每次加1 current_work_wheel_index_=GetWorkWheelIndex(current_work_wheel_index_+1);}// 5.下一级时间轮已经转了一圈,上一级时间轮加1
if(current_work_wheel_index_==0){{// 6.上一级时间轮bucket id加1 std::lock_guardlock(current_assistant_wheel_index_mutex_
);current_assistant_wheel_index_=GetAssistantWheelIndex(current_assistant_wheel_index_+1);}// 7. Cascade
(current_assistant_wheel_index_);}}}这里需要注意假设二级时间轮中有一个任务的时间周期就为512,那么在当前bucket回调中又会在当前bucket中增加一个任务,那么这个任务会执行2次,如何解决这个问题呢? Cyber中采用把这个任务放入上一级时间轮中,然后在触发一个周期之后,放到下一级的时间轮中触发。
总结经过上述分析,介绍了Cyber中定时器的实现原理,这里还有2个疑问1. 一是定时器是否为单线程,任务都是在单线程中的多个协程中执行???定时器的计数单独在一个线程中执行,具体的定时任务在协程池中执行,也就是说多个定时任务可以并发执行。
2. 当"TimingWheel::AddTask"中"work_wheel_index >= WORK_WHEEL_SIZE"并且"assistant_ticks == 1"时,假设原始的current_work_wheel_index_mutex_ = 200,消息触发周期为600个tick,那么按照上述计算方法得到的work_wheel_index = 800,real_work_wheel_index = 288,assistant_ticks = 1,那么"work_wheel_[real_work_wheel_index].AddTask(task)"会往288增加任务,实际上这个任务在88个tick之后就触发了???
往期回顾apollo介绍(一)apollo介绍之map模块(二)apollo介绍之localization模块(三)apollo介绍之planning模块(四)apollo介绍之Routing模块(六)
apollo介绍之Transform模块(七)apollo介绍之Canbus模块(八)apollo介绍之Control模块(九)apollo介绍之Perception模块(十七)apollo介绍之Audio模块(十八)
apollo预测模块分享(二十一)Cyber框架apollo介绍之cyber设计(五)apollo介绍之Cyber框架(十)apollo介绍之Cyber框架(十一)apollo介绍之Cyber定时器(十二)
apollo介绍之Cyber Component(十三)apollo介绍之Cyber Data(十四)apollo介绍之Cyber Scheduler调度(十五)apollo介绍之Cyber Async异步调用(十六)
apollo介绍之cyber启动(十九)高精度地图apollo介绍之map模块(二)高精度地图制作高精度地图制作(二)高精度地图制作(三)apollo简易制图过程(二十)apollo高精度地图可视化(二十二)
apollo高精度地图制作(二十三)apollo高精度地图标注(二十四)如果觉得本文对你有帮助,欢迎点赞、分享、关注3连 O(∩_∩)O~~
 sdf
sdf